What to expect from AI in finance, and which solutions do companies already use? Insights from the UK fintech week webinar

AI in finance, present and future: UK FinTech Week webinar highlights. Source: shutterstock.com
PaySpace Magazine Global has initiated the thread of articles on AI implementation in different areas. Mostly, it is about AI in the banking and financial sector. Artificial Intelligence has proven itself to be an efficient tool that revolutionizes the financial industry significantly, and most transformations seem to be beneficial and favorable. Moreover, we can see AI impacting Fintech as well. In this webinar, Professor Nir Vulkan will review existing applications and new emerging trends. In particular, he will show how new sources of data and new methods of analysis are likely to impact aspects of banking and finance.
As we’ve already mentioned above, Nir Vulkan, Associate Professor of Business Economics at Saïd Business School, and a long term member of the Oxford-Man Institute for Quantitative Finance was a speaker. He is Director of the Oxford Programmes on Fintech; Blockchain Strategy; and Algorithmic Trading and Chair of the Committee set up to advise the European Commission on AI in Banking and Finance.
This webinar, as a part of the UK FinTech Week, was supposed to cover:
- Review of AI applications in Finance
- Alternative financial data
- Review of AI methods used in the finance
- Wealth management and Robo advisors
- Latest in Algorithmic trading
Yes, I used “was supposed” phrase since professor Vulcan faced a highly engaged audience, which asked right and interesting questions. Thus, the speaker didn’t cover all the topics from the initial list because he chose to interact with the audience. And of course, 45 minutes wasn’t enough for such a complex and interesting topic.
The initial plan was presented by the speaker:
- AI in finance
- The OMI
- New data and New Methods
- Recent research
- Algo before and after
- Robo and Algo in times of COVID
First of all, Nir Vulcan emphasized that AI indeed plays a big role in FinTech nowadays, and mentioned the significant impact of AI on the finance sector overall. He also made a joke about AI definition, namely, 15-20 years before scientists also had similar (but not so advanced) technology, but they used to call it just computers or algorithms, while today all of those things are called AI.
Then he said that a lot is going on today, and this crisis accelerates some kind of financial-related things, and it somehow enhanced trust and confidence such things as online banking, electronic money, etc.
AI for consumer finance and credit scoring
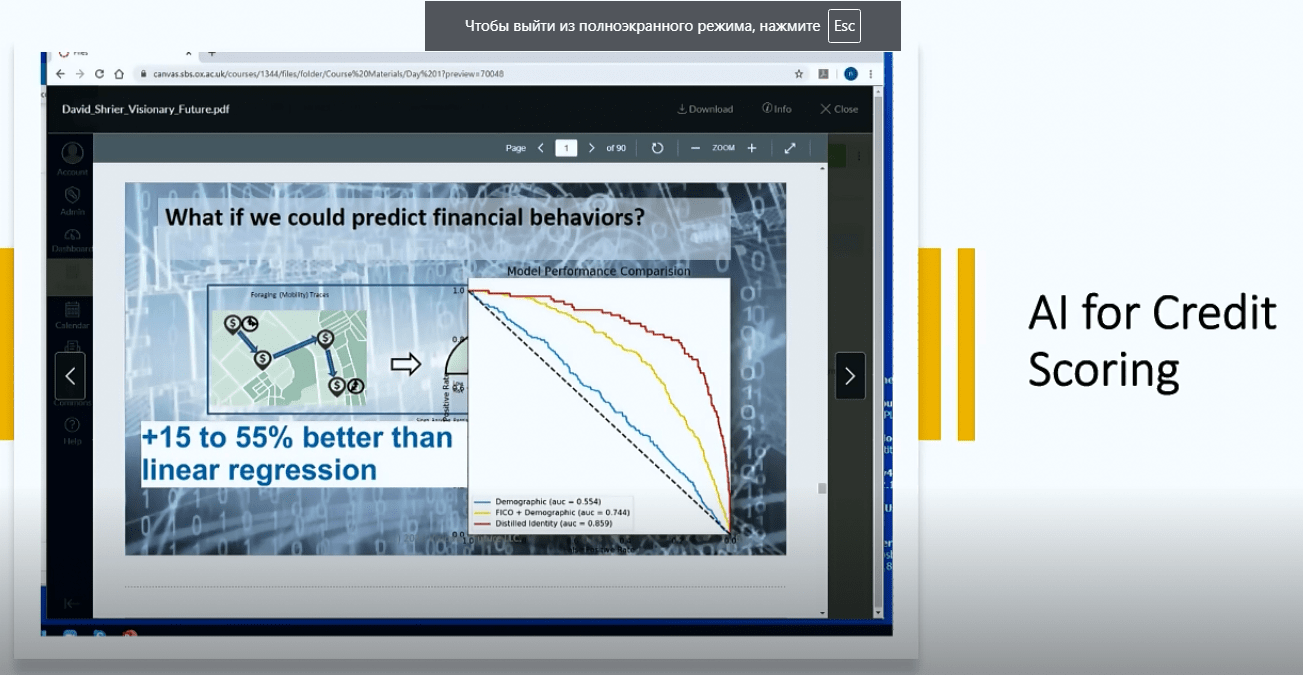
Slide from the webinar
AI for consumer finance and credit scoring was the first question, and Nir explained that the modern credit scoring system performs much better due to the info from social media. The major aim of such a system is to estimate the likelihood of whether a client will pay back, and set a certain number (a result of the estimation). The speaker noted that a phone basically contains more info about you than you think, so, in some way, it’s better to take data from phone and social media in order to get an accurate estimation. Particularly, the assessment is based on personality, mood, wellbeing, and other related things that can be got from a user’s phone. Thus, such data helps ML (machine learning) algorithms and modules to decide who can get a loan, and on what terms. Of course, such interference in personal life is conducted with a consumer’s consent.
Therefore, we can say that according to Nir Vulkan, personality is a good way to predict this very abovementioned likelihood. Even the smallest things count, such as the way we log in, how long we wait on the site before making a decision, etc.
AML & KYC

Slide from the webinar
AML and KYC was the next topic. According to the professor, these areas have also benefited from AI implementation, and today, costly and inefficient topic-related stuff can be rationalized and streamlined in the most efficient way.
The speaker has also raised an interesting issue. Namely, he asked, “Who is responsible, when the computer says no to a customer?” (related to credit score and loans issue). Hence, is it possible, that AI-trained system can learn to discriminate consumers (based on, let’s say, race, gender, etc.) Maybe AI learned to do this thing since it is so complicated?

Slide from the webinar
Anyway, human beings that are developing AI should be responsible for such possible consequences as discrimination-based actions and decisions.
Q&A session
Question #1: Will there be more risk of hacking in the newest AI system?
Nir answered that it is already a big issue, and it is not new. The more sophisticated system is, the more skillful hackers will be, so it doesn’t have to be an obstacle for developers to build new systems. On the other hand, you should always keep in mind security issues. After all, we should get used to the world where algorithms take more and more decisions.
Then, Nir Vulcan said that one of his aims was to take out the mystery from AI. He noted that AI is not that complicated, and it is not an enemy of humanity. Nonetheless, he warned the audience to be careful with it. The professor told listeners that the more data scientists have, the more chance to “overfit” they get, so the use of enormous amounts of data is still a moot point.
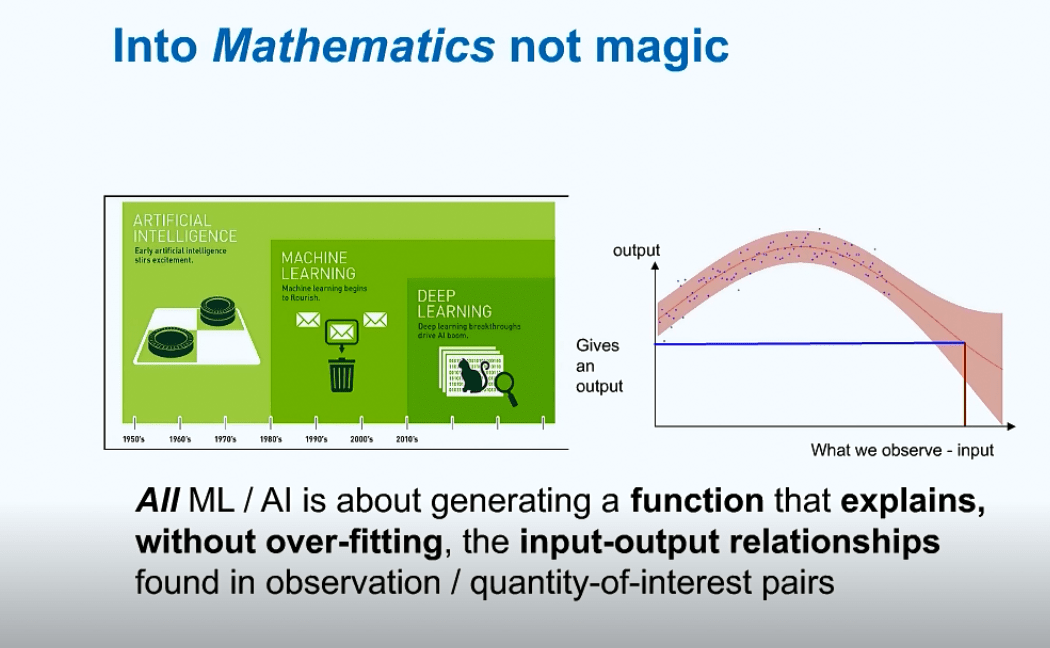
Slide from the webinar
Question #2: Can credit rating be using with social media and other mentioned stuff if somebody plans to use a similar credit score system in the different area, let’s say, at the East?
Nir said that a similar algorithm can be applied, but different patterns should be used in different points of the world. First and foremost, it is about independent cultures, and developers have to discover psychological nuances in order to find out whether customers will pay back or not. For example, the likelihood of loan repayment in China, the UK, and Sweden is different.
To sum up, it is clear that you have to train algorithms on the basis of the mindset of the audience you’re going to work with. Therefore, you’ll have to recalibrate the model in different markets.

Slide from the webinar
Question #3: How much data is enough for AI to be accurate?
It is a tricky question, but according to Nir Vulkan, it entirely depends on what you try to do. In 2020, there is no such phenomenon as a lack of data.
Moreover, he said that a simple model – (for instance, the one based on FB likes) doesn’t need much data. You can predict a user’s personality in 100 likes better than any of their friends. Overall, it depends, but algorithms learn really fast. What’s more, a simple model is not necessarily worse or more inaccurate than a complicated one. Too much data can lead to a complicated prediction, and there is no guarantee that it would be more precise. A simpler model can give better results, and it will be more understandable and straightforward. At some point, it can become more art than science.

Slide from the webinar
Question #4: We can see many applications for consumer credit scores and consumer lending, what about applications for company lending?
Nir answered that a lot of companies are working in this area, and they collect data about companies in the same way (from social media posts, reviews, etc).
Question #5: The use of personal data (i.e. 100 likes) seems to be an efficient way to accomplish estimation, but how can consumers give their consent for it, and where to start, if there are normally “100 pages” of terms&conditions agreement?
Nir said that they were working on it, while many of his colleagues stopped using smartphones, and this issue was one of the major reasons for it. According to the speaker, people, government, and regulators think about it, but the question “how to make data belong to us” is still relevant.
Nevertheless, Nir Vulcan stays optimistic about the privacy policy issue because he believes more and more regulatory standards are developing nowadays, and one day, this issue can be solved.
At the end of the webinar, he added that he didn’t cover all the topics he planned to cover, but he firmly believes that the COVID crisis will be good for automation overall.

Slide from the webinar
SEE ALSO:








